Explicação do relatório P1
Das curvas de rotação ao lenteamento fraco: como testar a resposta gravitacional média da EFT
Consulte o relatório de avaliação original:
1. ChatGPT: https://chatgpt.com/share/6a00cd62-6e34-83eb-b165-6ec09e3519cc
2. Gemini: https://gemini.google.com/share/773ec96d75a0
3. Grok: https://grok.com/share/bGVnYWN5LWNvcHk_c0b4fa65-0e86-4adb-9b58-5617d616dc04
4. Qwen: https://chat.qwen.ai/s/22ab9336-671f-420a-a7fa-43e24774bb2a?fev=0.2.46
5. DeepSeek: https://chat.deepseek.com/share/tj6k7hb5owtoldg2bm
Nota de leitura |
Este é um texto explicativo, não outro relatório acadêmico. Ele se baseia no relatório P1 original, preserva as figuras e tabelas principais e acrescenta, em cada etapa importante, uma explicação pública de “o que isso significa”. |
Este texto interpreta apenas as conclusões do P1 dentro de seus conjuntos de dados, livro de parâmetros e protocolo estatístico já definidos: no teste conjunto das curvas de rotação galácticas (RC) e do lenteamento fraco galáxia-galáxia (GGL), o modelo de resposta gravitacional média da EFT fica claramente à frente da linha de base mínima DM_RAZOR testada aqui. |
Este texto não interpreta o P1 como uma conclusão de que “a matéria escura foi derrotada”. O P1 é apenas o primeiro passo da série P; ele testa o nível observável da “base gravitacional média” da EFT, não o conteúdo completo de toda a teoria EFT. |
0 | Entender o P1 em cinco minutos: o que exatamente está sendo feito?
Podemos pensar no P1 como um experimento de “verificação cruzada entre sondas”. Ele não pergunta apenas se um modelo consegue ajustar um conjunto de dados; coloca duas leituras gravitacionais completamente diferentes no mesmo banco de auditoria: as curvas de rotação (RC) leem a dinâmica nos discos galácticos, enquanto o lenteamento fraco galáxia-galáxia (GGL) lê a resposta gravitacional projetada em escalas maiores.
- As RC funcionam como um “velocímetro”: indicam a que velocidade o gás e as estrelas giram em diferentes raios do disco de uma galáxia.
- O GGL funciona como uma “balança”: a partir da leve curvatura da luz de fundo causada por galáxias em primeiro plano, infere a distribuição média de gravidade ou massa em torno das galáxias em escalas maiores.
- A pergunta central do P1 é esta: um mesmo modelo consegue primeiro aprender uma regularidade a partir das RC e depois transferi-la para o GGL mantendo a coerência?
A frase mais importante do P1 |
O P1 eleva o limiar de comparação de “quão bem ajusta separadamente” para “se consegue fechar entre sondas”. Só quando o modelo tem bom desempenho sob o mapeamento correto e o sinal colapsa quando esse mapeamento é embaralhado é mais provável que ele tenha captado uma estrutura gravitacional compartilhada entre RC e GGL. |
Tabela 0 | Os números centrais do P1 e como lê-los como leitor geral
Indicador | Leitura dentro do P1 / P1A | Como interpretá-lo como leitor geral |
Ajuste conjunto ΔlogL_total | Na comparação principal, a EFT em relação ao DM_RAZOR alcança 1155–1337 | Diferença de pontuação total quando os dois conjuntos de dados são combinados; quanto maior, melhor a explicação global. |
Força de fechamento ΔlogL_closure | Na comparação principal, a EFT alcança 172–281 e o DM_RAZOR 127 | Capacidade de prever GGL após inferir apenas com RC; quanto maior, mais “autocoerente entre sondas”. |
Controle negativo shuffle | Após embaralhar RC-bin→GGL-bin, o sinal de fechamento da EFT cai para 6–23 | Se a correspondência correta é rompida, a vantagem deveria desaparecer; quanto mais desaparece, mais sinais espúrios são descartados. |
Teste de pressão P1A com múltiplos DM | DM 7+1 + DM_STD, mantendo EFT_BIN como controle | O P1A não olha apenas para o DM_RAZOR mínimo: coloca vários ramos DM reforçados, de baixa dimensão e auditáveis, dentro do mesmo protocolo de fechamento. |
1 | Por que fazer o P1: onde a cosmologia em escala galáctica está travada hoje?
O problema das escalas galácticas continua difícil porque a “necessidade de gravidade ou massa adicional” não é apenas um fenômeno das curvas de rotação. Muitas observações mostram uma relação muito estreita entre a matéria bariônica visível das galáxias e as leituras dinâmicas ou de lenteamento efetivamente medidas. Para as rotas de matéria escura, isso implica coordenar com grande precisão halos escuros, feedback bariônico, história de formação galáctica e erros sistemáticos de observação; para as rotas de gravidade sem matéria escura, implica que um modelo não pode ficar bonito apenas em RC, mas também precisa se manter no lenteamento fraco, nas leis de escala populacionais e nos controles negativos.
Essa é precisamente a motivação do P1: ele não parte de que “a matéria escura está errada” nem de que “a EFT tem de estar correta”. Ele toma uma proposição testável e a submete a exame: se a resposta gravitacional média da EFT deixa, no fechamento entre sondas RC→GGL, um sinal reprodutível e transferível.
Contexto bibliográfico externo: por que esta janela RC+GGL é importante? |
A relação de aceleração radial (RAR) proposta por McGaugh, Lelli e Schombert em 2016 mostra uma correlação estreita, com pouca dispersão, entre a aceleração observada traçada pelas curvas de rotação e a aceleração prevista a partir da matéria bariônica. Isso torna o acoplamento entre bárions e resposta gravitacional um problema inevitável para teorias em escala galáctica. |
Brouwer et al. 2021 usaram o lenteamento fraco KiDS-1000 para estender a RAR a acelerações mais baixas e raios maiores, comparando MOND, a gravidade emergente de Verlinde e modelos LambdaCDM; também apontaram que as diferenças entre galáxias de tipo inicial e tardio, halos gasosos e a conexão galáxia–halo continuam sendo peças explicativas essenciais. |
Mistele et al. 2024 usaram ainda o lenteamento fraco para inferir curvas de velocidade circular em galáxias isoladas, relatando que elas não apresentam queda clara até centenas de kpc e até cerca de 1 Mpc, além de serem compatíveis com a BTFR. Isso indica que o lenteamento fraco está se tornando uma leitura externa importante para testar a resposta gravitacional em escala galáctica. |
Por isso, o valor do P1 não está em ser “o primeiro a falar de RC e GGL juntos”, mas em colocá-los dentro de um protocolo auditável composto por um mapeamento fixo, um livro de parâmetros, fechamento RC-only→GGL, controle negativo por shuffle e testes de pressão P1A com múltiplos DM.
2 | O que EFT significa no P1: não é Effective Field Theory
Aqui, EFT designa a Teoria do filamento de energia (Energy Filament Theory, EFT), não a Effective Field Theory usual em física. No relatório técnico P1, o uso da EFT é muito prudente: ela não compete como uma teoria final completa, mas primeiro é comprimida em uma parametrização observável, ajustável e refutável da “resposta gravitacional média”.
Em linguagem simples: o P1 ainda não discute todas as fontes microscópicas da gravidade adicional, nem pretende provar toda a EFT de uma vez. Ele faz apenas uma pergunta mais estreita e mais dura: se existe certa resposta gravitacional média em escala galáctica, ela consegue primeiro explicar as RC e depois prever o GGL ao ser transferida de uma sonda para outra?
Que parte da EFT o P1 captura? |
O P1 captura a “base gravitacional média” (mean gravity floor): uma contribuição média, estatisticamente estável e transferível entre amostras. |
O P1 ainda não trata da “base de ruído” (stochastic / noise floor): termos aleatórios, diferenças individuais ou dispersão adicional que poderiam surgir de processos microscópicos de flutuação. |
O P1 tampouco discute o mecanismo microscópico completo, abundâncias, tempos de vida ou restrições cosmológicas globais. Ele é o primeiro passo da série P, não o veredito final. |
3 | O plano da série P: por que o primeiro passo começa pela “base média”?
A série P pode ser entendida como o programa de busca observacional da EFT. Ela não desdobra todas as teses de uma vez; primeiro retira a peça mais fácil de submeter a dados públicos. A estratégia do P1 é testar primeiro o termo médio: se a resposta gravitacional média nem sequer fecha de RC para GGL, discutir termos de ruído mais complexos ou mecanismos microscópicos ficaria sem uma porta de entrada sólida.
Tabela 1 | Posicionamento em camadas da série P
Camada | Pergunta formulada | Lugar no P1 |
P1 | A resposta gravitacional média consegue fechar de RC para GGL? | Pergunta principal do relatório atual |
P1A | Se fortalecermos o lado DM, a conclusão permanece estável? | Apêndice B: teste de pressão DM 7+1 + DM_STD |
Série P posterior | Pode ser ampliada para mais dados, mais sondas e erros sistemáticos mais complexos? | Direção de trabalho posterior |
Problemas mais profundos | Como se conectam o termo médio, o termo de ruído e o mecanismo microscópico? | Fora do alcance das conclusões do P1 |
4 | Quais são os dados: o que RC e GGL nos dizem separadamente?
4.1 Curvas de rotação RC: o “medidor de velocidade” do disco galáctico
As curvas de rotação registram a velocidade com que o gás e as estrelas giram em diferentes raios em relação ao centro galáctico. Quanto maior a velocidade, maior a força centrípeta necessária nesse raio e, portanto, maior a gravidade efetiva. O P1 usa a base de dados SPARC; após o pré-processamento, inclui 104 galáxias e 2295 pontos de velocidade, divididos em 20 RC-bin.
4.2 Lenteamento fraco GGL: a “balança gravitacional” em escalas maiores
O lenteamento fraco galáxia-galáxia mede como galáxias em primeiro plano curvam levemente a luz de galáxias de fundo. Ele corresponde à resposta gravitacional projetada em escalas maiores, da ordem do halo, e não depende dos detalhes da dinâmica do gás no disco. O P1 usa os dados públicos de GGL do KiDS-1000 / Brouwer et al. 2021: 4 bins de massa estelar, 15 pontos radiais por bin, 60 pontos no total, com a covariância completa.
4.3 Mapeamento fixo: por que 20 RC-bin → 4 GGL-bin é crucial?
O P1 conecta os 20 RC-bin aos 4 GGL-bin por meio de uma regra fixa: cada GGL-bin corresponde a 5 RC-bin e é calculado por média ponderada pelo número de galáxias. Esse mapeamento permanece igual para todos os modelos; é uma restrição rígida para o teste de fechamento e para uma comparação justa.
Por que não ajustar o mapeamento depois de ver os dados? |
Se fosse permitido escolher a posteriori “quais RC-bin correspondem a quais GGL-bin”, um modelo poderia fabricar fechamento ajustando as correspondências. O P1 bloqueia de antemão o mapeamento 20→4 e usa um controle negativo shuffle para rompê-lo deliberadamente, justamente para avaliar se o sinal de fechamento depende de uma correspondência fisicamente razoável. |
5 | Modelos e método: o que exatamente o P1 compara?
5.1 Lado EFT: resposta gravitacional média de baixa dimensão
No lado EFT, usa-se um termo adicional de velocidade de baixa dimensão para descrever a resposta gravitacional média: a forma do termo adicional é controlada por uma função núcleo adimensional f(r/ℓ), em que ℓ é uma escala global, e a amplitude é dada por RC-bin. Diferentes funções núcleo representam diferentes inclinações iniciais, velocidades de transição e caudas de longo alcance, sendo usadas como testes de robustez.
5.2 Lado DM: a comparação principal do texto e o Apêndice P1A devem ser lidos separadamente
Na comparação principal, DM_RAZOR é uma linha de base NFW minimizada e auditável: fixa a relação c–M e não inclui halo-to-halo scatter, contração adiabática, feedback core, não esfericidade nem termos ambientais. A vantagem desse desenho é controlar os graus de liberdade e facilitar a reprodução; sua desvantagem é não representar todos os modelos LambdaCDM nem todos os modelos possíveis de halo de matéria escura.
Por isso, no Apêndice B (P1A), o lado DM é transformado em um conjunto de “testes de pressão padronizados”: sem alterar o mapeamento compartilhado nem o protocolo de fechamento, são acrescentados gradualmente ramos de baixa dimensão como SCAT, AC, FB, HIER_CMSCAT, CORE1P, lensing m e a linha de base combinada DM_STD, mantendo EFT_BIN como referência. O P1A pode ser entendido assim: não se compara apenas contra uma linha de base DM mínima; coloca-se um conjunto de mecanismos DM comuns e auditáveis dentro da mesma “régua de fechamento”.
Formulação precisa das conclusões usada neste texto |
Texto principal: a série EFT supera claramente o DM_RAZOR mínimo na comparação principal. |
Apêndice B / P1A: com vários ramos DM reforçados de baixa dimensão e auditáveis, junto com o teste de pressão DM_STD, alguns ajustes conjuntos DM podem melhorar, mas a força de fechamento não elimina a vantagem de EFT_BIN. |
Portanto, a formulação mais prudente é: dentro do alcance dos dados, do mapeamento, do livro de parâmetros e do protocolo de fechamento do P1/P1A, a resposta gravitacional média da EFT mostra consistência mais forte entre conjuntos de dados; isso não equivale a descartar todos os modelos de matéria escura. |
5.3 Teste de fechamento: a gramática experimental mais importante do P1
1. Ajustar usando apenas RC e obter um conjunto de amostras posteriores RC-only.
2. Sem permitir novo ajuste com GGL, usar diretamente as posteriores de RC para prever GGL.
3. Calcular, com a covariância completa, a pontuação preditiva GGL logL_true sob o mapeamento correto.
4. Permutar aleatoriamente a correspondência RC-bin→GGL-bin e calcular o controle negativo logL_perm.
5. Subtrair as duas quantidades para obter a força de fechamento: ΔlogL_closure = <logL_true> − <logL_perm>.
Analogia simples |
O teste de fechamento se parece com uma segunda prova em outra sala: o modelo aprende primeiro na sala RC e depois responde na sala GGL. Se ele realmente aprendeu uma regularidade compartilhada, e não uma técnica local, deveria continuar respondendo bem ao mudar de sala; se a correspondência entre as salas é deliberadamente embaralhada, a vantagem deveria desaparecer. |
5.4 Antes de ler as tabelas técnicas: quatro entradas a fixar
Tabela 5.4 | Roteiro de leitura da próxima série de tabelas técnicas horizontais
Entrada | O que observar | Por que importa |
Tabela S1a | Pontuação total de ajuste conjunto RC+GGL | Responde “olhando os dois conjuntos de dados juntos, quem oferece uma explicação global mais forte”. |
Tabela S1b | Força de fechamento, shuffle e varreduras de robustez | Responde “se o que foi aprendido em RC pode ser transferido para GGL”. |
Tabela B0 | Definições de múltiplos ramos DM reforçados no P1A | Evita reduzir o P1 a “foi comparado apenas com o DM_RAZOR mínimo”. |
Tabela B1 | Scoreboard de fechamento e ajuste conjunto do P1A | Verifica se, após reforçar DM, a vantagem de fechamento desaparece. |
Nota de diagramação |
A página seguinte começa em orientação horizontal para preservar integralmente a tabela larga do relatório original, sem eliminar colunas nem comprimi-la até ficar ilegível. A explicação do texto já oferece primeiro uma leitura para o público geral; as tabelas horizontais servem para quem precisa conferir números e ramos de modelo. |
Figura 0.1 | Entender de relance o fluxo do teste de fechamento do P1
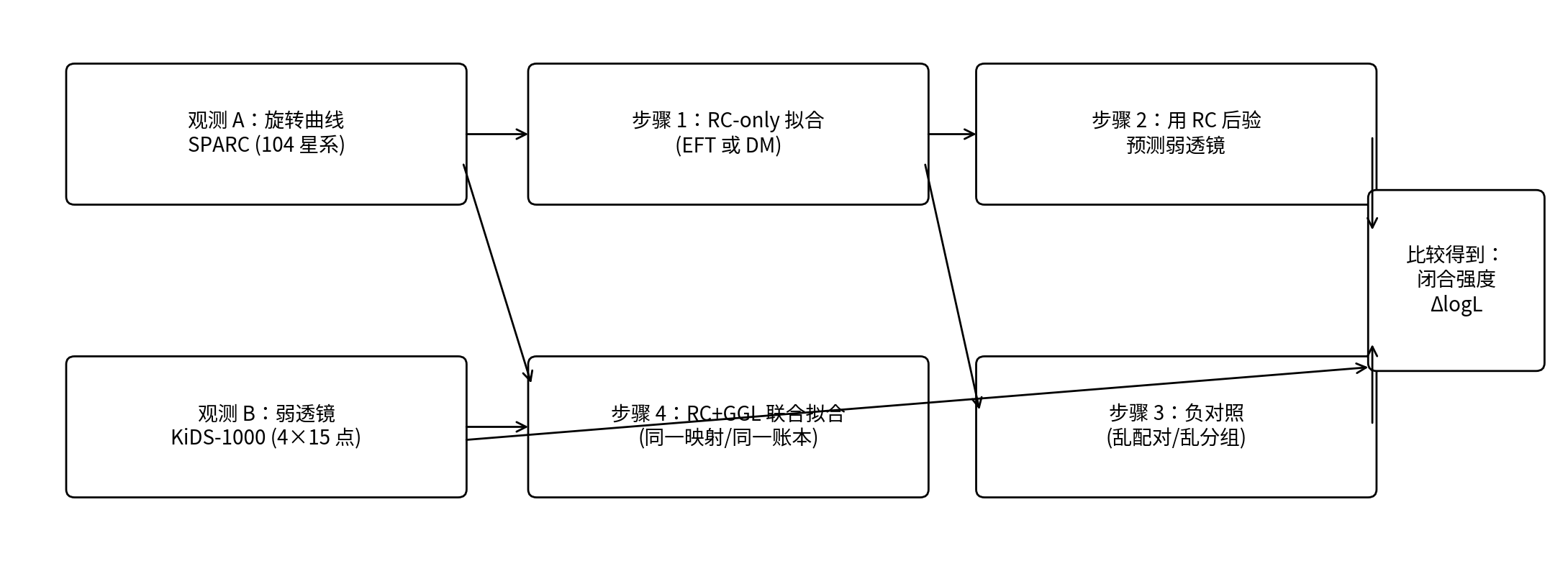
Nota: a cadeia superior é o “teste de fechamento” (ajustar apenas com RC → prever GGL com as posteriores de RC); a cadeia inferior é o “ajuste conjunto” (RC+GGL são pontuados juntos). À direita, compara-se o mapeamento real com o mapeamento embaralhado para obter a força de fechamento ΔlogL.
6 | Tabelas técnicas principais: tabelas centrais do relatório original e tabelas P1A
Tabela S1a | Indicadores principais de ajuste conjunto (RC+GGL, Strict; preservados do relatório original)
Modelo (workspace) | Núcleo W | k | logL_total conjunto (best) | ΔlogL_total vs DM | AICc | BIC |
DM_RAZOR | none | 20 | -16927.763 | 0.0 | 33895.885 | 34010.811 |
EFT_BIN | none | 21 | -15590.552 | 1337.21 | 31223.501 | 31344.155 |
EFT_WEXP | exponential | 21 | -15668.83 | 1258.932 | 31380.057 | 31500.711 |
EFT_WYUK | yukawa | 21 | -15772.936 | 1154.827 | 31588.268 | 31708.922 |
EFT_WPOW | powerlaw_tail | 21 | -15633.321 | 1294.442 | 31309.038 | 31429.692 |
Tabela S1b | Indicadores de fechamento e robustez (Strict; preservados do relatório original)
Modelo (workspace) | ΔlogL de fechamento (true-perm) | ΔlogL após controle negativo shuffle | Faixa de ΔlogL na varredura σ_int | Faixa de ΔlogL na varredura R_min | Faixa de ΔlogL na varredura cov-shrink |
DM_RAZOR | 126.678 | 22.725 | — | — | — |
EFT_BIN | 231.611 | 14.984 | 459–1548 | 1243–1289 | 1337–1351 |
EFT_WEXP | 171.977 | 6.04 | 408–1471 | 1169–1207 | 1259–1277 |
EFT_WYUK | 179.808 | 14.688 | 380–1341 | 1065–1099 | 1155–1166 |
EFT_WPOW | 280.513 | 6.672 | 457–1500 | 1203–1247 | 1294–1308 |
Tabela B0 | Definição dos ramos DM reforçados no P1A (preservada do Apêndice B do relatório original)
Workspace | dm_model | Parâmetros adicionados (≤1) | Motivação física (núcleo) | Princípio de implementação (auditável) |
|---|---|---|---|---|
DM_RAZOR | NFW (fixed c–M, no scatter) | — | Linha de base de halo LambdaCDM minimizada e auditável; usada como contraste estrito frente à EFT | Mapeamento compartilhado fixo; livro de parâmetros estrito; como baseline, usada apenas para comparação relativa |
DM_RAZOR_SCAT | NFW + c–M scatter(legacy) | σ_logc | Existe dispersão na relação c–M; aproximada com um scatter log-normal de um parâmetro | ≤1 novo parâmetro; mantém-se o mapeamento compartilhado; o ganho de fechamento é o critério de aceitação |
DM_RAZOR_AC | NFW + Adiabatic Contraction(legacy) | α_AC | A queda de bárions pode induzir contração adiabática do halo; aproximada por uma intensidade de um parâmetro | ≤1 novo parâmetro; não altera o mapeamento; reportam-se mudanças em AICc/BIC e ganho de fechamento |
DM_RAZOR_FB | NFW + feedback core(legacy) | log r_core | O feedback pode formar um core na região interna; aproximado por uma escala core de um parâmetro | ≤1 novo parâmetro; mesmo critério de fechamento/controle negativo; a melhora RC-only não é o único objetivo |
DM_HIER_CMSCAT | Hierarchical c–M scatter + prior | σ_logc(hier) | Hierarquização mais padrão c_i∼logN(c(M_i),σ_logc); afeta ao mesmo tempo a posterior conjunta de RC e GGL | Prior explícito; c_i latentes marginalizados; mantém baixa dimensionalidade e auditabilidade |
DM_CORE1P | 1‑parameter core proxy (coreNFW/DC14‑inspired) | log r_core | Usa um proxy core de um parâmetro para o efeito principal do baryonic feedback, evitando detalhes de alta dimensão da formação estelar | Citam-se referências padrão; ≤1 novo parâmetro; vinculado ao teste de fechamento |
DM_RAZOR_M | NFW + lensing shear‑calibration nuisance | m_shear(GGL) | Absorve o erro sistemático-chave do lado do lenteamento fraco em um parâmetro efetivo, reduzindo o risco de confundir sistemática com física | O nuisance fica contabilizado explicitamente; não pode retroagir sobre RC; os resultados são avaliados sobretudo pela robustez do fechamento |
DM_STD | Standardized DM baseline (HIER_CMSCAT + CORE1P + m) | σ_logc + log r_core (+ m_shear) | Integra simultaneamente as três objeções frequentes mais comuns em uma linha de base padrão que continua de baixa dimensão | Livro de parâmetros + critérios de informação reportados juntos; fechamento como indicador principal; usado como contraste de defesa DM mais forte |
Tabela B1 | Scoreboard P1A (quanto maior, melhor; preservado do Apêndice B do relatório original)
Ramo do modelo (workspace) | Δk | RC-only best logL_RC (Δ) | Força de fechamento ΔlogL_closure (Δ) | Joint best logL_total (Δ) |
DM_RAZOR | 0 | -15702.654 (+0.000) | 122.205 (+0.000) | -27347.068 (+0.000) |
DM_RAZOR_SCAT | 1 | -15702.294 (+0.361) | 121.236 (-0.969) | -23153.311 (+4193.758) |
DM_RAZOR_AC | 1 | -15703.689 (-1.035) | 121.531 (-0.674) | -23982.557 (+3364.511) |
DM_RAZOR_FB | 1 | -15496.046 (+206.609) | 129.454 (+7.249) | -27478.531 (-131.463) |
DM_HIER_CMSCAT | 1 | -15702.644 (+0.010) | 121.978 (-0.227) | -23153.160 (+4193.908) |
DM_CORE1P | 1 | -15723.158 (-20.504) | 122.056 (-0.149) | -27336.258 (+10.810) |
DM_RAZOR_M | 0 (+m) | -15702.654 (+0.000) | 122.205 (+0.000) | -27340.451 (+6.617) |
DM_STD | 2 (+m) | -15832.203 (-129.549) | 105.690 (-16.515) | -22984.445 (+4362.623) |
EFT_BIN | 1 | -14631.537 (+1071.117) | 204.620 (+82.415) | -19001.142 (+8345.926) |
Como ler a Tabela B1 (scoreboard P1A) |
• Δk: graus de liberdade adicionados (um valor maior implica um modelo mais complexo; mais complexo não significa melhor). • Observe sobretudo duas colunas: a força de fechamento ΔlogL_closure(Δ) (quanto maior, mais “autocoerente na transferência”) e Joint best logL_total(Δ) (pontuação total do ajuste conjunto). • O (Δ) entre parênteses indica a diferença em relação ao DM_RAZOR, facilitando a comparação direta. |
• A pergunta que esta tabela mais procura responder é: quando a linha de base DM é “razoavelmente reforçada”, a vantagem de fechamento desaparece? • Dica de leitura: a pontuação conjunta do DM_STD melhora de forma muito clara, mas a força de fechamento cai; EFT_BIN continua mantendo uma força de fechamento maior. |
Resumo em uma frase: dentro deste conjunto de reforços DM de baixa dimensão e auditáveis, melhorar o ajuste conjunto não produz automaticamente um fechamento mais forte; o fechamento, isto é, a transferibilidade, continua sendo o critério-chave. |
7 | Como ler os resultados principais
7.1 Ajuste conjunto: vendo os dois conjuntos de dados juntos, a comparação principal dá pontuação maior à EFT
A Tabela S1a e a Figura S4 mostram que, com os mesmos dados, o mesmo mapeamento compartilhado e uma escala de parâmetros aproximadamente semelhante, a série EFT obtém em relação ao DM_RAZOR um ΔlogL_total conjunto de 1155–1337. Para o leitor geral, isso significa que, sob a mesma regra de pontuação aplicada a RC e GGL em conjunto, o modelo principal EFT alcança uma pontuação total mais alta.
7.2 Teste de fechamento: o que o P1 mais quer enfatizar é a “transferibilidade”
Uma força de fechamento alta indica que os parâmetros inferidos pelo modelo apenas com RC, sem voltar a olhar para GGL, preveem melhor o GGL. No relatório P1, o ΔlogL_closure da EFT é 172–281, enquanto o DM_RAZOR alcança 127. Esse resultado é mais importante do que dizer que “ambos ajustam razoavelmente bem”, porque limita a liberdade do modelo no segundo conjunto de dados.
7.3 Controle negativo: por que o “colapso do sinal” é uma boa notícia?
Quando o P1 embaralha aleatoriamente a correspondência de grupos RC-bin→GGL-bin, o sinal de fechamento da EFT cai para a ordem de 6–23. Para o leitor geral, essa etapa equivale a uma “prova antitrapaça”: se a vantagem de fechamento viesse apenas do código, das unidades, da covariância ou de uma coincidência de ajuste, talvez continuasse aparecendo ao embaralhar as correspondências; mas o resultado real é o colapso da vantagem, mostrando que ela depende do mapeamento correto.
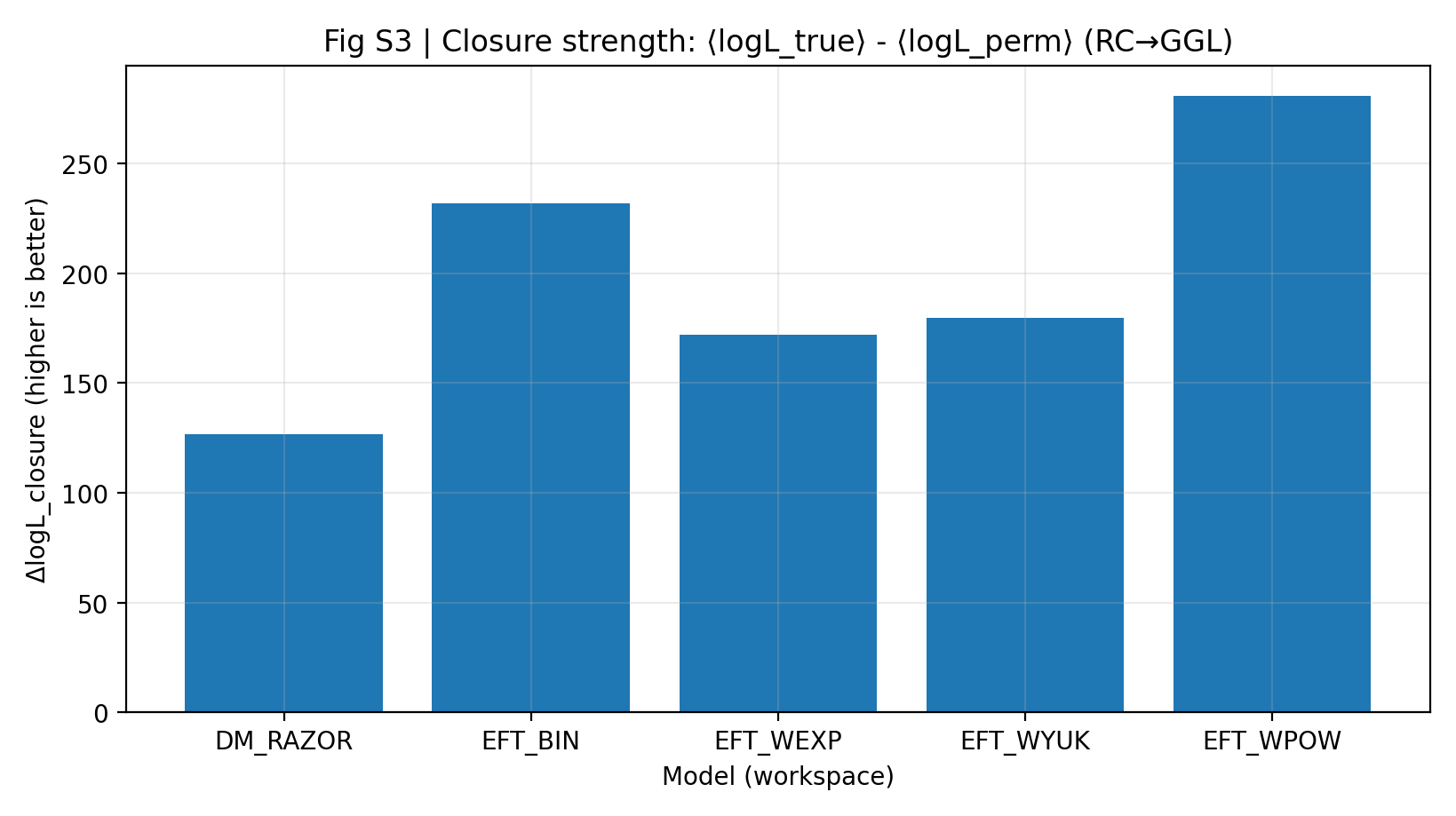
Figura S3 | Força de fechamento (quanto maior, melhor): vantagem média de log-verossimilhança na predição RC-only → GGL.
Como interpretar esta figura |
Esta figura é o núcleo do P1. Quanto mais alta a barra, mais a informação que o modelo aprendeu de RC pode ser transferida para GGL. |
A série EFT fica, no conjunto, acima do DM_RAZOR, indicando que no experimento “aprender primeiro RC e depois prever GGL” a EFT tem um fechamento entre sondas mais forte. |
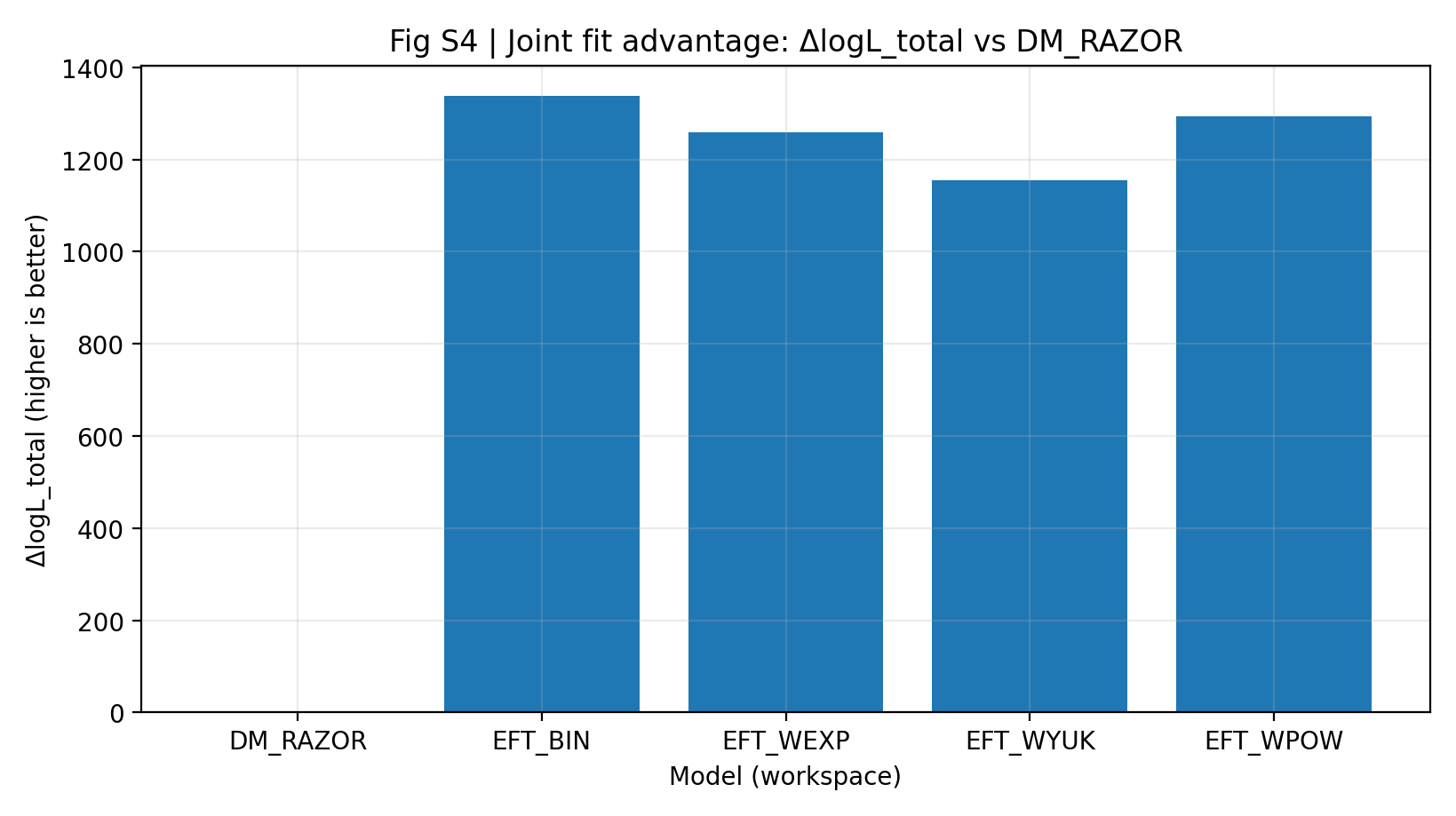
Figura S4 | Vantagem de ajuste conjunto (quanto maior, melhor): best logL_total de RC+GGL em relação a DM_RAZOR.
Como interpretar esta figura |
Esta figura mostra a pontuação total depois de combinar RC e GGL. |
Toda a série EFT fica claramente acima de 0, indicando que a vantagem da EFT na comparação principal não é um fenômeno local de um único ponto, mas o desempenho global da análise conjunta. |
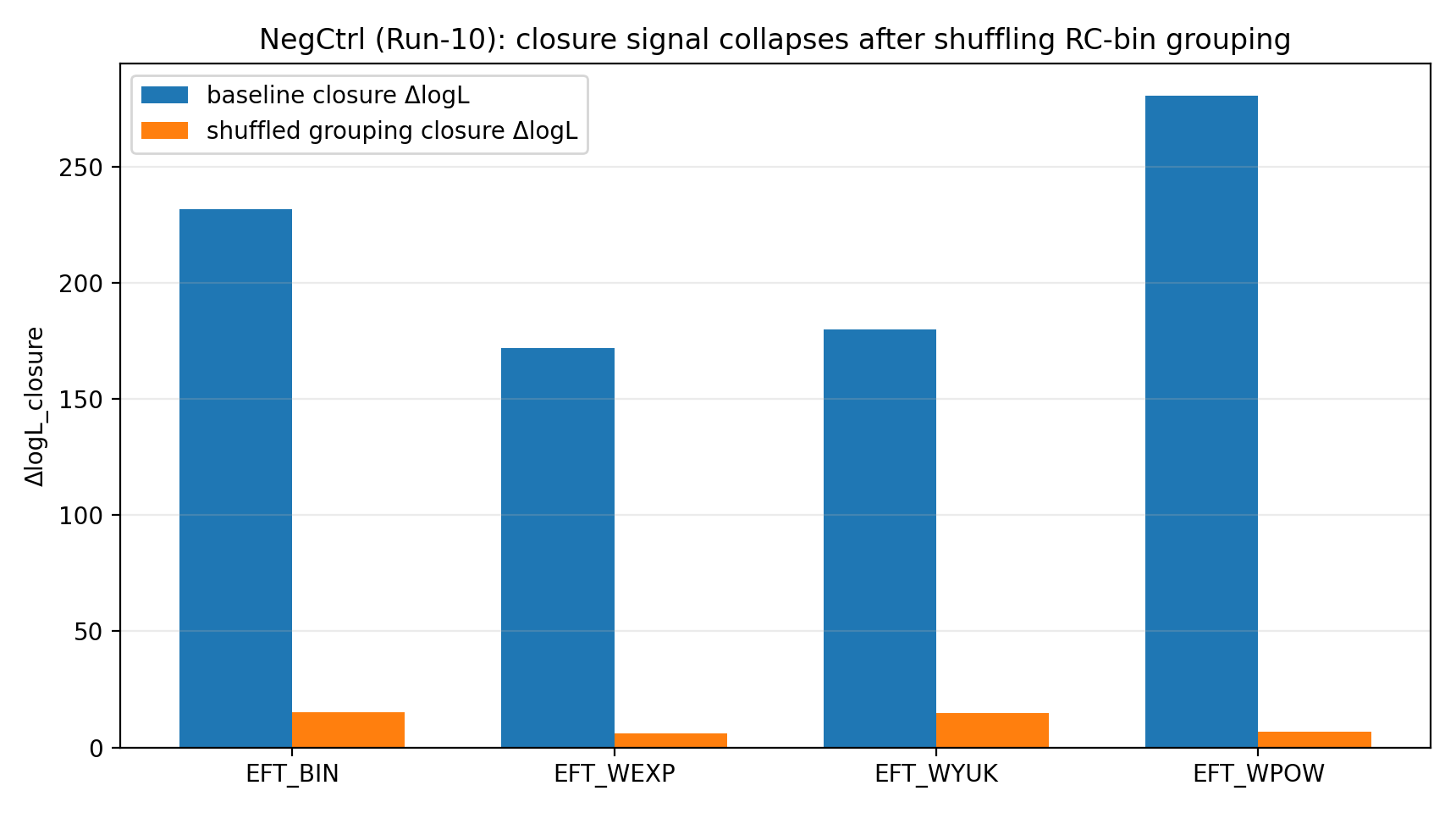
Figura R1 | Controle negativo: o sinal de fechamento cai claramente após o shuffle dos grupos.
Como interpretar esta figura |
Esta figura mostra que, uma vez embaralhada a relação correta dos bins RC↔GGL, o sinal de fechamento cai de forma notável. |
Isso faz o resultado do P1 se parecer mais com uma consistência real dentro do mapeamento entre dados do que com uma coincidência numérica obtida com qualquer mapeamento. |
8 | Robustez e controles: como o P1 evita que isso seja “apenas um bom ajuste por parâmetros”?
Um relatório técnico costuma ser questionado por estas dúvidas: a vantagem vem de uma suposição de ruído, de uma região central dos dados, de algum tratamento da covariância ou de sobreajuste? O P1 responde com vários testes de pressão.
Tabela 2 | Como ler a robustez e os controles negativos no P1
Teste | Que dúvida tenta descartar | Leitura |
Varredura σ_int | Se houver dispersão desconhecida adicional em RC, a conclusão permanece estável? | Ao relaxar os erros de RC, a ordem e a escala da vantagem da EFT permanecem estáveis. |
Varredura R_min | Se não confiarmos plenamente na região central das galáxias, a conclusão permanece estável? | Após recortar a região central, a EFT mantém uma vantagem positiva. |
Varredura cov-shrink | Se a estimativa da covariância GGL for incerta, a ordem é sensível? | Ao contrair a covariância em direção a uma matriz diagonal, a vantagem é pouco sensível. |
Escada de ablação | A EFT está ajustando à força por meio de complexidade desnecessária? | O EFT_BIN completo mostra necessidade segundo os critérios de informação. |
Predição LOO deixando de fora | O modelo só sabe explicar dados que já viu? | Ao deixar de fora um GGL bin, ainda mostra generalização relativamente forte. |
RC-bin shuffle | O fechamento vem de um mapeamento real? | Ao embaralhar os grupos, o fechamento cai, apoiando a dependência do mapeamento. |
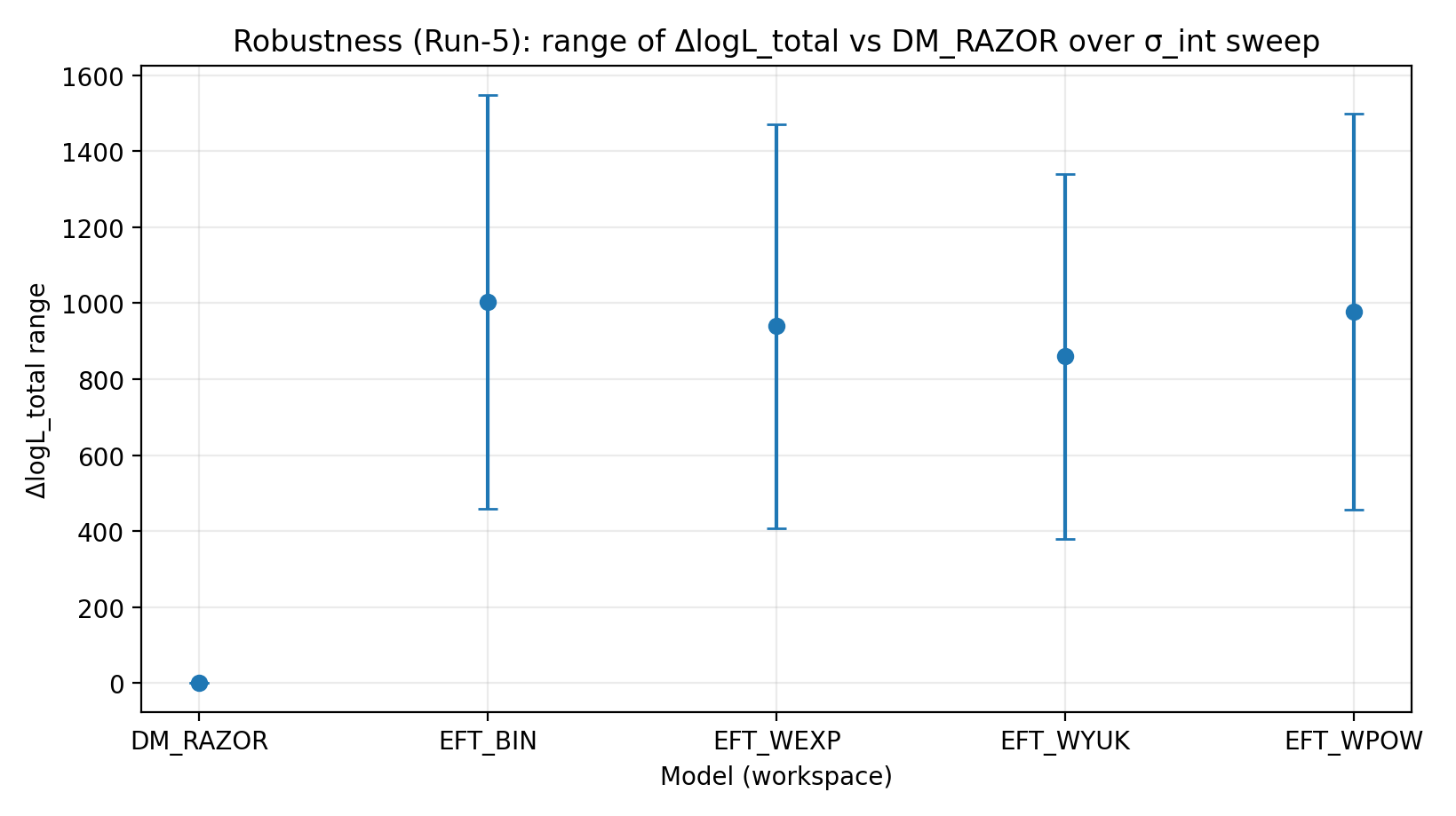
Figura R2 | Faixa de ΔlogL_total sob a varredura de σ_int (quanto maior, melhor).
Como interpretar esta figura |
Verifica se a vantagem da EFT persiste quando se altera a hipótese sobre a dispersão intrínseca de RC. |
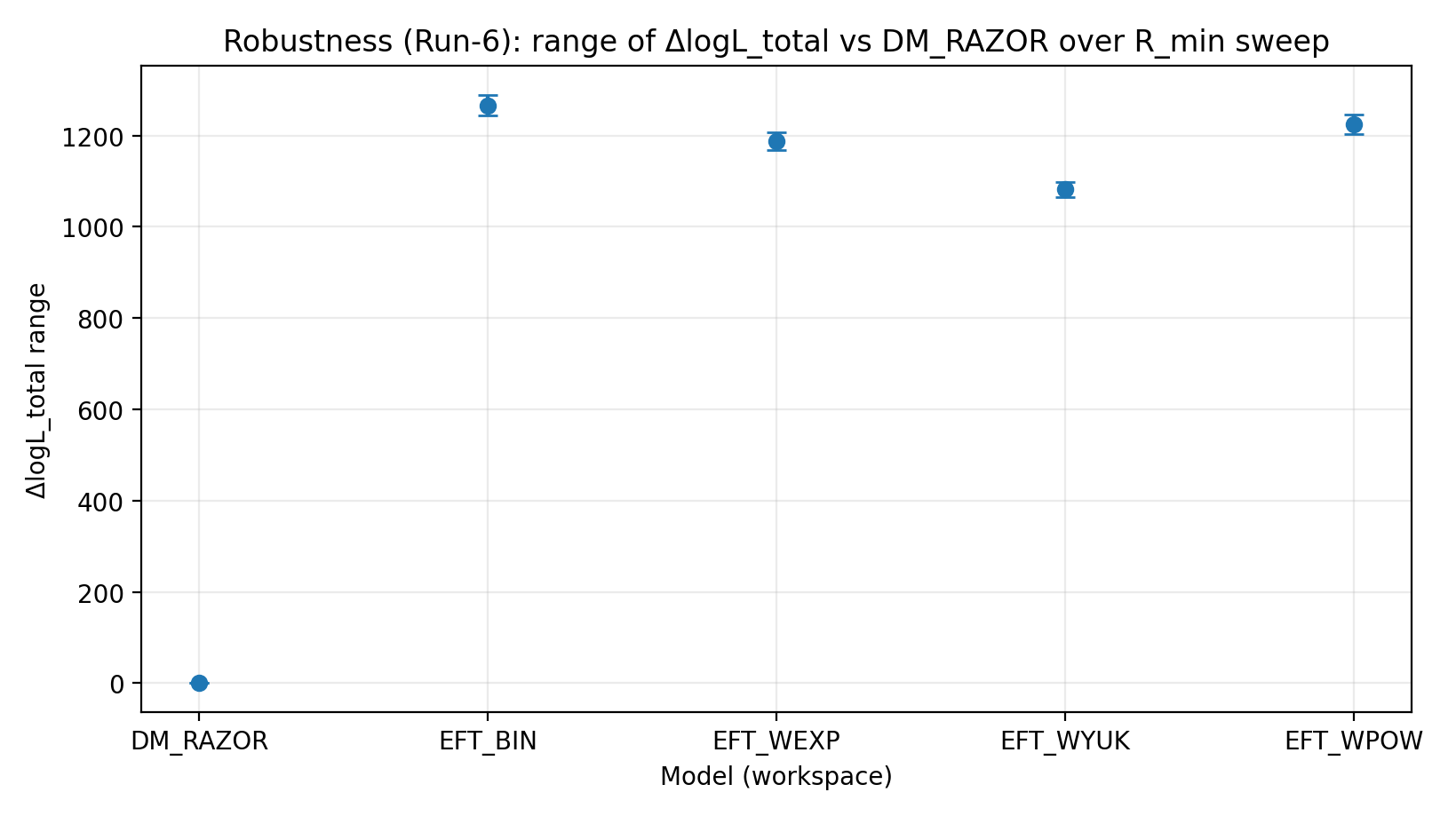
Figura R3 | Faixa de ΔlogL_total sob a varredura de R_min (quanto maior, melhor).
Como interpretar esta figura |
Verifica se a vantagem da EFT permanece estável após recortar a região central complexa. |
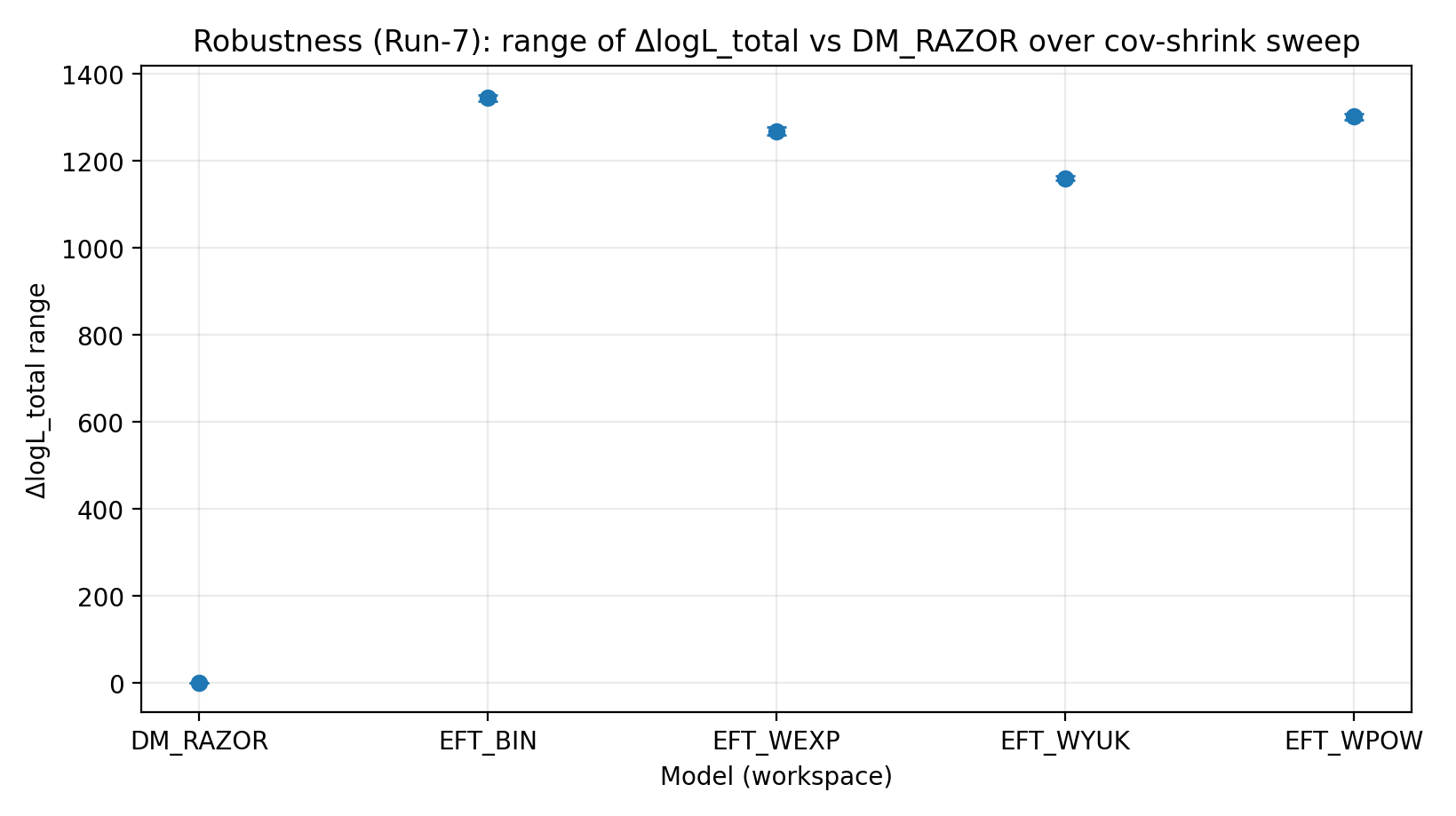
Figura R4 | Faixa de ΔlogL_total sob a varredura cov-shrink (quanto maior, melhor).
Como interpretar esta figura |
Verifica se a ordem é sensível a mudanças no tratamento da covariância do lenteamento fraco. |
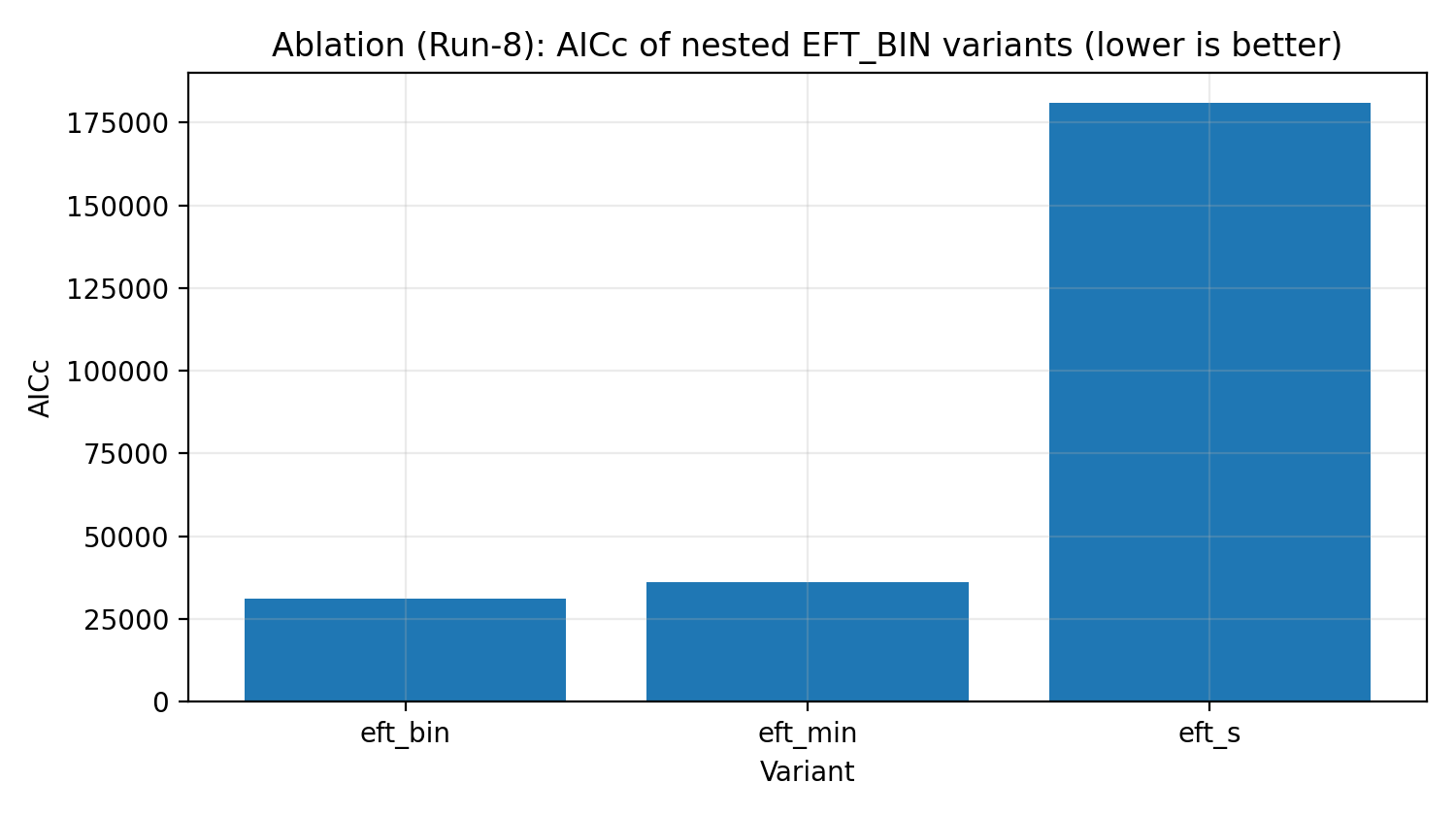
Figura R5 | Escada de ablação de EFT_BIN (AICc, quanto menor, melhor).
Como interpretar esta figura |
Verifica se o EFT_BIN completo é necessário para explicar os dados, e não apenas adiciona parâmetros em excesso. |
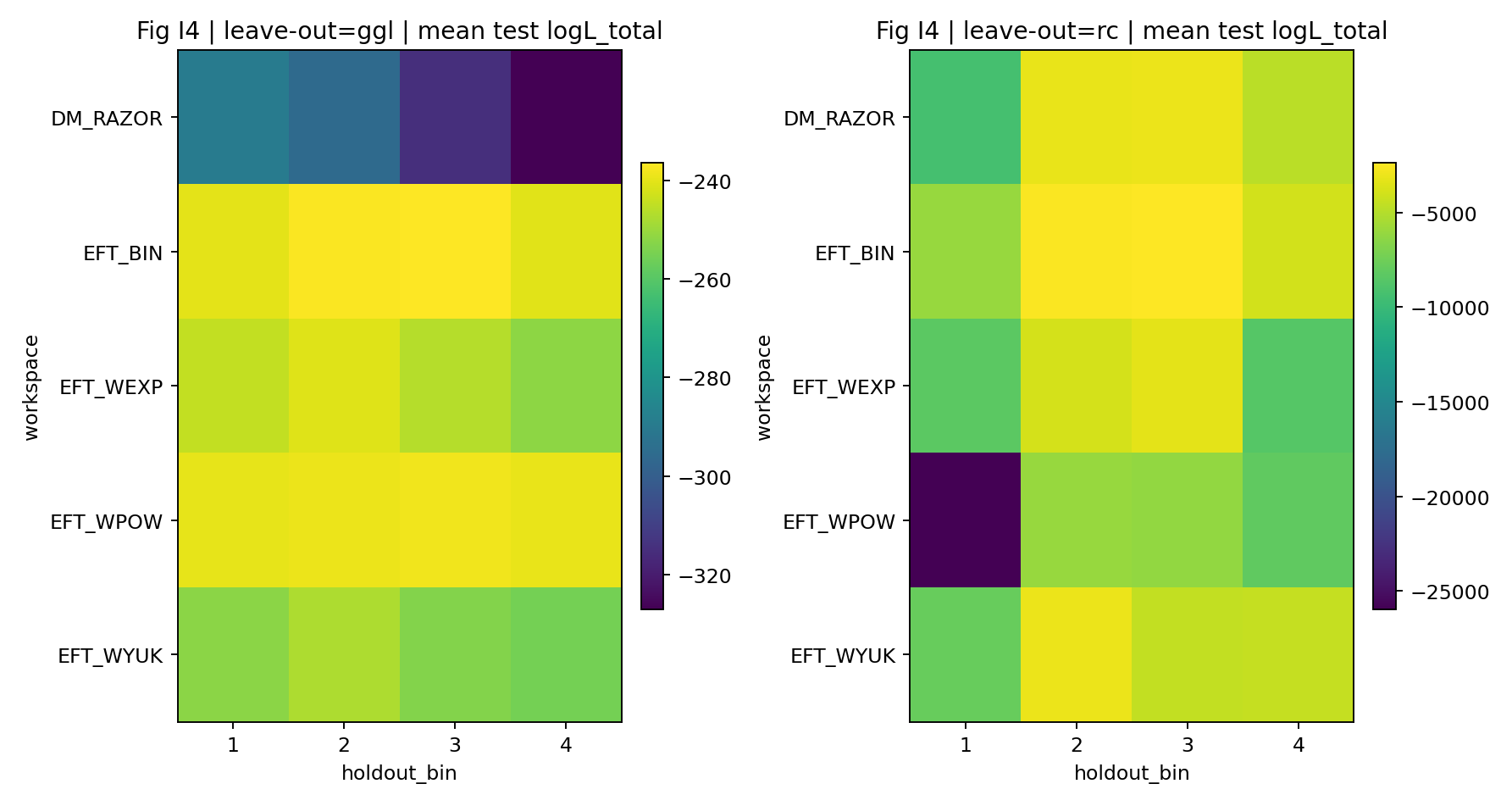
Figura R6 | LOO: distribuição de log-verossimilhança ao deixar um bin de fora.
Como interpretar esta figura |
Verifica se o modelo conserva capacidade preditiva em GGL bins não vistos. |
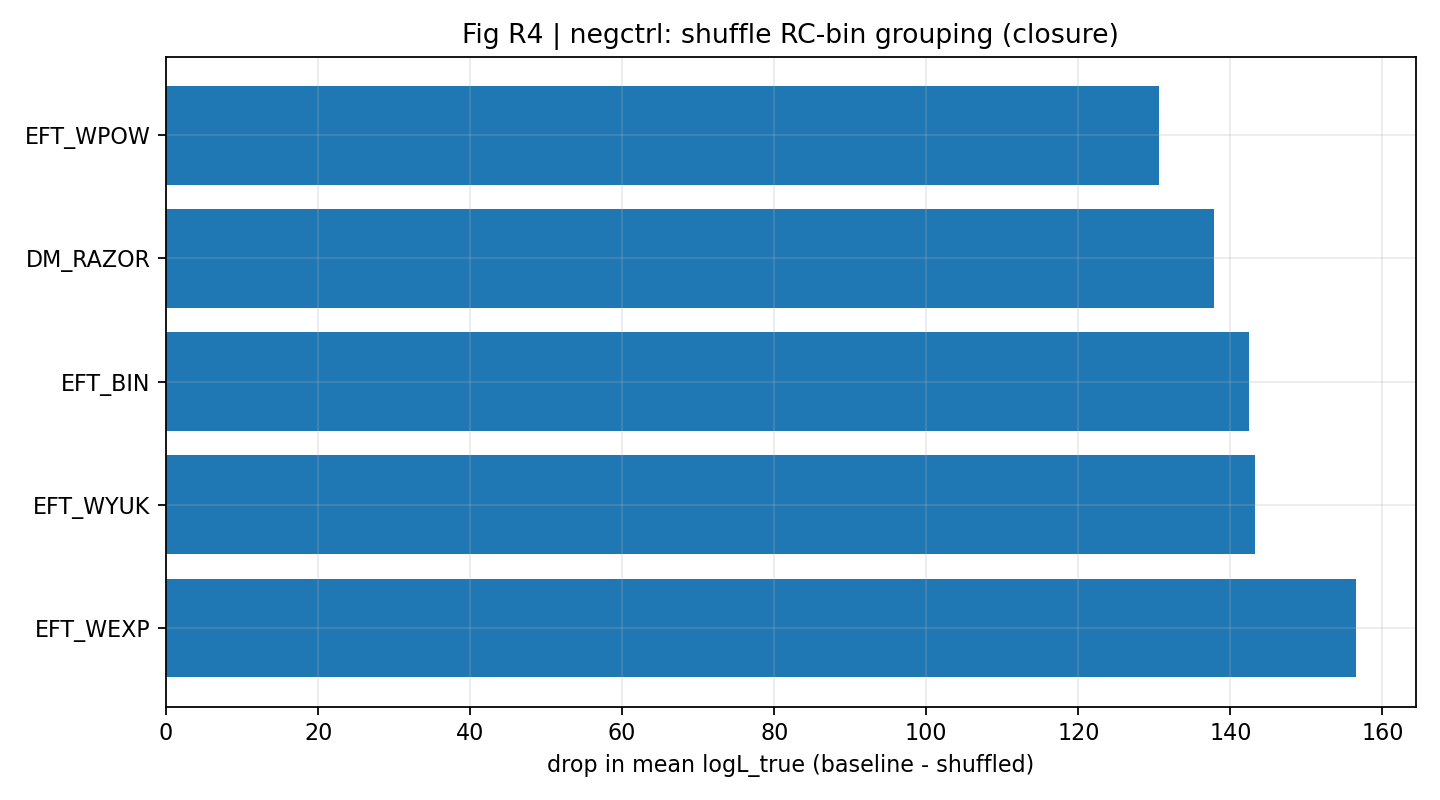
Figura R7 | Controle negativo: o shuffle do mapeamento reduz claramente a média logL_true de fechamento.
Como interpretar esta figura |
Mostra ainda, a partir da média logL_true, que o fechamento depende do mapeamento correto entre conjuntos de dados. |
9 | P1A: por que “há vários modelos DM no apêndice” é uma correção essencial?
Esta seção não pergunta “a EFT venceu apenas um DM_RAZOR mínimo?”, mas: se reforçarmos a linha de base DM dentro de uma faixa de baixa dimensão, reprodutível e com livro de parâmetros claro (P1A), as conclusões do teste de fechamento e do ajuste conjunto são reescritas? Em outras palavras, o P1A procura reduzir a objeção de que “foi escolhida apenas uma linha de base DM fraca demais” e levar a discussão para esta pergunta: sob um conjunto auditável de reforços DM, ainda existe diferença no desempenho de fechamento?
O desenho do P1A não tenta esgotar todas as possibilidades de modelagem de halos LambdaCDM nem converter o lado DM em uma máquina de ajuste de alta dimensão e impossível de auditar. Ele escolhe reforços de baixa dimensão, reprodutíveis e com livro de parâmetros claro: scatter de concentração, contração adiabática, feedback core, prior hierárquico de scatter c–M, proxy core de um parâmetro, nuisance de calibração shear no lenteamento fraco e o DM_STD combinado.
Leitura principal do P1A |
Entre os três ramos legacy, apenas feedback/core traz pequena melhora líquida para a força de fechamento; SCAT e AC não geram melhora líquida de fechamento. |
DM_HIER_CMSCAT, DM_RAZOR_M e DM_CORE1P têm efeito muito pequeno sobre a força de fechamento ou não mostram melhora líquida significativa. |
DM_STD pode melhorar claramente o joint logL, mas a força de fechamento diminui, sugerindo que melhora principalmente a flexibilidade do ajuste conjunto, e não a potência de predição transferida RC→GGL. |
EFT_BIN continua mantendo, na Tabela B1 do P1A, uma força de fechamento mais alta e uma vantagem de ajuste conjunto; portanto, a tese central do P1 não deve ser simplificada como “venceu apenas o DM_RAZOR mínimo”. |
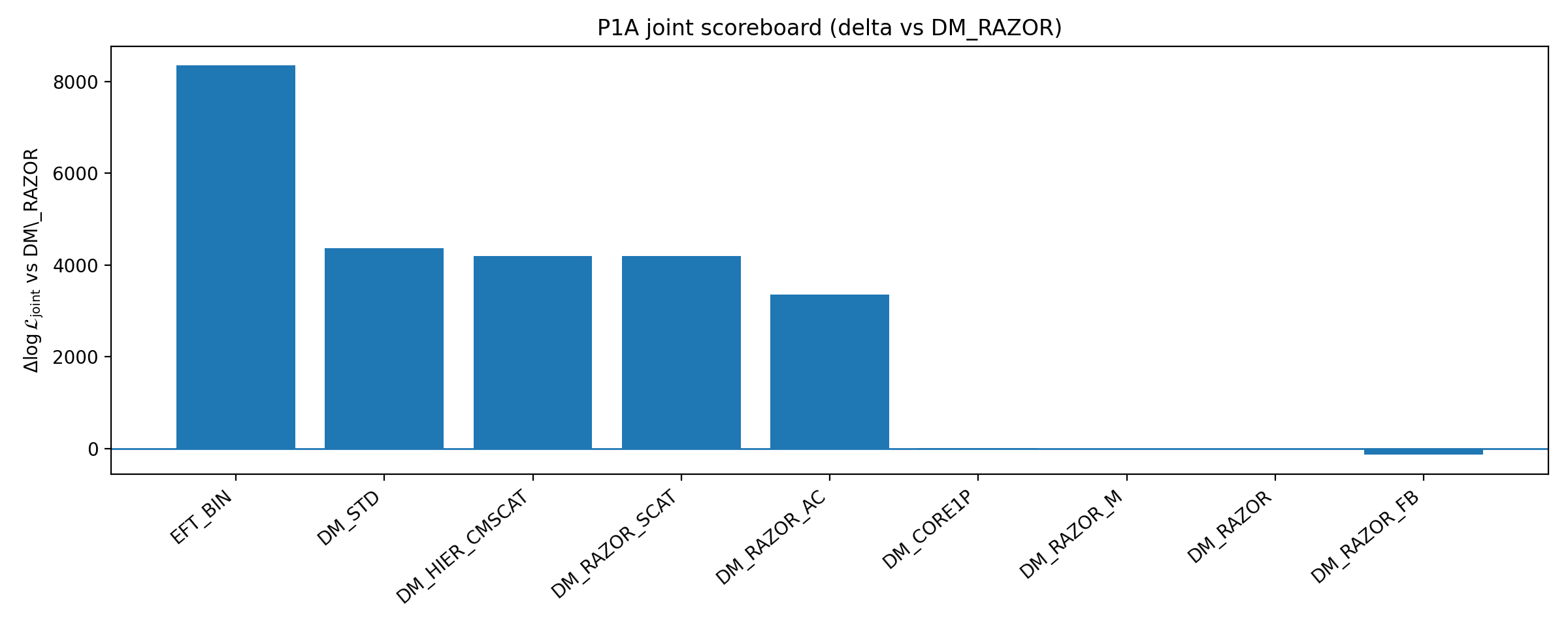
Figura B1 | Scoreboard P1A: ΔlogL de fechamento e conjunto em relação à baseline (quanto maior, melhor).
Como interpretar esta figura |
Esta figura mostra o desempenho de vários ramos DM reforçados frente à linha de base. |
Seu significado não é “descartar todos os DM”, mas mostrar que, dentro da faixa de reforços DM de baixa dimensão e auditáveis escolhida pelo P1A, o DM reforçado não elimina a vantagem de fechamento do EFT_BIN. |
10 | Significado do experimento P1: por que vale a pena fazê-lo?
10.1 Significado metodológico: colocar o “fechamento entre sondas” acima do “ajuste de uma única sonda”
Teorias em escala galáctica caem facilmente na discussão sobre se um modelo consegue ou não ajustar um conjunto de curvas de rotação. O P1 eleva a pergunta em um nível: os parâmetros que você aprendeu com RC conseguem prever o lenteamento fraco sem reajustar o GGL? Assim, o P1 deixa de ser uma “competição de ajuste” e passa a ser um “teste de predição transferida”.
10.2 Significado de transparência: tratar a cadeia reprodutível como parte do resultado
Uma contribuição importante do P1 é publicar juntos os dados, as tabelas e figuras, os rótulos de execução, os controles negativos, o pacote de reprodução e a cadeia de auditoria. Isso importa tanto para apoiadores quanto para críticos: a discussão pode voltar ao mesmo conjunto de dados públicos, ao mesmo mapeamento, aos mesmos scripts e aos mesmos indicadores, em vez de comparar apenas slogans.
10.3 Significado físico: oferece um forte teste de pressão para a direção de “gravidade sem matéria escura”
Na direção da gravidade sem matéria escura, muitos modelos conseguem explicar parte das curvas de rotação ou da RAR; o mais difícil é também passar pela leitura de lenteamento fraco e mostrar, com controles negativos, que o sinal depende do mapeamento correto. O sentido do P1 é colocar a resposta gravitacional média da EFT dentro de um protocolo semelhante a um “exame externo”: RC é o campo de treinamento, GGL é o campo de transferência e shuffle é o campo antitrapaça.
10.4 Este é um experimento importante para o campo da “gravidade sem matéria escura”?
Com cautela: se o processamento de dados, o pacote de reprodução e o protocolo de fechamento do P1 resistirem à revisão externa, ele pode ser considerado um experimento de fechamento RC+GGL digno de atenção dentro da direção de gravidade sem matéria escura / gravidade modificada. Sua importância não está na frase “derrotar a matéria escura”, mas em oferecer um critério entre sondas que pode ser copiado, desafiado e ampliado.
Já existe uma estrutura de predição RC+GGL com fechamento igualmente alto? |
Existem estruturas e tradições observacionais relacionadas: MOND/RAR organiza muito bem muitos fenômenos de curvas de rotação; o trabalho de RAR com lenteamento fraco KiDS-1000 também comparou MOND, a gravidade emergente de Verlinde e modelos LambdaCDM; LambdaCDM também pode explicar parte dos fenômenos de lenteamento fraco/dinâmica por meio da conexão galáxia–halo, halos gasosos e modelagem de feedback. |
Mas a afirmação precisa do P1 não é “não existe no mundo nenhuma outra estrutura capaz de explicar RC+GGL”; é que, sob o próprio protocolo público do P1 — mapeamento fixo, fechamento RC-only→GGL, controle negativo shuffle, livro de parâmetros e testes de pressão P1A com múltiplos DM —, a EFT reporta desempenho de fechamento mais forte. |
Dito de outro modo, o que mais merece verificação externa no P1 é que ele propõe um protocolo de comparação concreto e reprodutível. Se, em etapas posteriores, MOND/RAR, LambdaCDM/HOD, simulações hidrodinâmicas ou outras estruturas de gravidade modificada alcançarem, sob o mesmo protocolo, pontuações de fechamento iguais ou superiores, essa será uma linha de trabalho muito valiosa. |
11 | O que o P1 pode inferir e o que não pode inferir
Tabela 3 | Limites das conclusões do P1
Pode-se inferir | Sob os dados RC+GGL do P1, o mapeamento fixo e o protocolo principal de comparação, a série EFT obtém, em relação ao DM_RAZOR mínimo, ajuste conjunto mais alto e maior força de fechamento. |
Pode-se inferir | Dentro da faixa P1A de reforços DM de baixa dimensão e auditáveis, vários reforços DM não eliminam a vantagem de fechamento do EFT_BIN. |
Pode-se inferir | O controle negativo shuffle mostra que o sinal de fechamento depende do mapeamento correto entre conjuntos de dados, e não aparece com qualquer mapeamento arbitrário. |
Não se pode inferir | Não se pode dizer que o P1 já refutou todos os modelos de matéria escura. O P1A não esgota modelos não esféricos, dependências ambientais, conexões galáxia–halo complexas, feedback de alta dimensão nem simulações cosmológicas completas. |
Não se pode inferir | Não se pode dizer que a teoria EFT completa tenha sido provada a partir de primeiros princípios. O P1 testa apenas a camada fenomenológica de resposta gravitacional média. |
Não se pode inferir | Não se pode dizer que todos os erros sistemáticos tenham sido descartados. O P1 fornece evidência de robustez apenas dentro dos testes de pressão e do alcance de auditoria listados. |
12 | Perguntas frequentes: as dúvidas mais comuns do leitor geral
Q1: Isso diz que “a matéria escura não existe”?
Não. A conclusão do P1 deve ser limitada aos dados, ao protocolo e aos modelos de comparação deste texto. O P1A já vai além do DM_RAZOR mínimo, mas ainda assim não representa todos os modelos possíveis de matéria escura.
Q2: Isso diz que “a EFT já está provada”?
Também não. O P1 testa a EFT como uma parametrização da resposta gravitacional média e mostra desempenho mais forte no fechamento RC→GGL; o mecanismo microscópico e a teoria completa não são conclusões do P1.
Q3: Por que não falar diretamente em valores de significância σ?
O P1 usa uma pontuação de verossimilhança unificada, critérios de informação e diferenças de fechamento. ΔlogL é uma vantagem relativa sob a mesma regra de pontuação; não equivale a um único valor σ.
Q4: Por que embaralhar RC-bin→GGL-bin?
É um controle negativo. Um sinal real entre sondas deve depender do mapeamento correto; se, depois do embaralhamento, ele continuasse igualmente forte, isso sugeriria vieses de implementação ou um sinal estatístico espúrio.
Q5: Qual deveria ser o próximo passo do P1?
Estender o mesmo protocolo a mais dados, mais comparadores DM, erros sistemáticos mais complexos e mais estruturas de gravidade modificada; especialmente permitir que equipes externas repliquem o teste sob o mesmo indicador de fechamento.
13 | Pequeno glossário de termos
Tabela 4 | Pequeno glossário de termos
Termo | Explicação em uma frase |
Curva de rotação (RC) | Relação raio–velocidade no disco galáctico, usada para inferir a gravidade efetiva dentro do disco. |
Lenteamento fraco (GGL) | Medição da distribuição média de gravidade/massa em torno de galáxias em primeiro plano por meio da distorção estatística das formas de galáxias de fundo. |
Teste de fechamento | Usar as posteriores de RC para prever GGL e comparar com um controle negativo de mapeamento embaralhado. |
Controle negativo | Destruir deliberadamente uma estrutura-chave para ver se o sinal desaparece; usado para descartar sinais espúrios. |
Halo NFW | Perfil de densidade de halo de matéria escura usado com frequência em modelos de matéria escura fria. |
Relação c–M | Relação entre a concentração c e a massa M de um halo de matéria escura; permitir ou não scatter afeta a flexibilidade do modelo. |
DM_STD | Ramo padronizado de teste de pressão DM no P1A que combina vários reforços DM de baixa dimensão e um nuisance de lenteamento. |
ΔlogL | Diferença de log-verossimilhança entre dois modelos sob a mesma regra de pontuação; um valor positivo indica que o primeiro é melhor. |
Covariância | Descrição matricial das correlações entre pontos de dados; em dados de lenteamento fraco, normalmente deve-se usar a covariância completa. |
14 | Roteiro de leitura recomendado e entradas de citação
1. Leia primeiro as seções 0–2 deste texto para construir a pergunta do P1 e a posição prudente da EFT dentro do P1.
2. Depois observe as Figuras S3 e S4, e as Tabelas S1a/S1b, para entender a força de fechamento, o ajuste conjunto e o controle negativo.
3. Se a preocupação for se a linha de base DM é fraca demais, vá diretamente à seção 9 e à Tabela B1 / Figura B1.
4. Para uma revisão técnica, volte ao relatório técnico P1 v1.1, ao suplemento Tables & Figures e ao full_fit_runpack.
Principais entradas de arquivo |
Relatório técnico P1 (nível de publicação, Concept DOI): 10.5281/zenodo.18526334 |
Pacote completo de reprodução P1 (Concept DOI): 10.5281/zenodo.18526286 |
Base de conhecimento estruturada da EFT (opcional, Concept DOI): 10.5281/zenodo.18853200 |
Nota de licença: o relatório técnico usa CC BY-NC-ND 4.0; o pacote completo de reprodução usa CC BY 4.0 (conforme o relatório técnico e o arquivo Zenodo). |
15 | Referências e contexto externo
McGaugh, S. S., Lelli, F., & Schombert, J. M. (2016). The Radial Acceleration Relation in Rotationally Supported Galaxies. Physical Review Letters, 117, 201101. DOI: 10.1103/PhysRevLett.117.201101.
Famaey, B., & McGaugh, S. S. (2012). Modified Newtonian Dynamics (MOND): Observational Phenomenology and Relativistic Extensions. Living Reviews in Relativity, 15, 10. DOI: 10.12942/lrr-2012-10.
Brouwer, M. M., Oman, K. A., Valentijn, E. A., et al. (2021). The weak lensing radial acceleration relation: Constraining modified gravity and cold dark matter theories with KiDS-1000. Astronomy & Astrophysics, 650, A113. DOI: 10.1051/0004-6361/202040108.
Mistele, T., McGaugh, S., Lelli, F., Schombert, J., & Li, P. (2024). Indefinitely Flat Circular Velocities and the Baryonic Tully-Fisher Relation from Weak Lensing. The Astrophysical Journal Letters, 969, L3 / arXiv:2406.09685.
Bullock, J. S., & Boylan-Kolchin, M. (2017). Small-Scale Challenges to the LambdaCDM Paradigm. Annual Review of Astronomy and Astrophysics, 55, 343–387. DOI: 10.1146/annurev-astro-091916-055313.
Lelli, F., McGaugh, S. S., & Schombert, J. M. (2016). SPARC: Mass Models for 175 Disk Galaxies with Spitzer Photometry and Accurate Rotation Curves. The Astronomical Journal, 152, 157. DOI: 10.3847/0004-6256/152/6/157.
Navarro, J. F., Frenk, C. S., & White, S. D. M. (1997). A Universal Density Profile from Hierarchical Clustering. Astrophysical Journal, 490, 493.
Dutton, A. A., & Macciò, A. V. (2014). Cold dark matter haloes in the Planck era: evolution of structural parameters for NFW haloes. Monthly Notices of the Royal Astronomical Society, 441, 3359–3374.